Paper: In Search of an Understandable Consensus Algorithm (Extended Version) by Diego Ongaro and John Ousterhout.
In this post, I share my notes on the core ideas of a distributed consensus algorithm, raft, why we use it and how it works. We will also analyse one of the important figures (safety rules: figure 8) from the paper.
My main goal with this post is to present and explain the important parts of the paper, and as a next step, one can go ahead and read the paper already having an idea of the crux of the algorithm so it becomes easier to read through and explore the parts one is interested in. This is kind of also how I personally prefer to approach reading longer texts or books.
In further posts, we'll be implementing raft in go. It took me a good amount of time, many readings of the raft paper, and referring to various other discussion forums to fully understand and implement raft. I have tried to distill my learnings into concise notes here for easier understanding.
Table of contents
-
ii. Log Replication
iii. Safety
Problems with Distributed Systems
Early implementations of distributed systems like MapReduce, GFS, VMware FT, and Primary-secondary replicated relational DBs faced challenges with single points of failure due to centralized control components.
In MapReduce, the Coordinator was a single point of failure, halting jobs if it failed.
In GFS, the Coordinator Server, responsible for managing metadata and chunk locations, could become a bottleneck if it becomes unavailable.
VMware FT replicated servers but relied on a test-and-set service to pick the primary server.
A primary-secondary replicated db which is asynchronously replicated could be made highly available to serve reads, but it may return stale data, and may not be able to failover to another instance if the primary fails due to replication lag. If replication is made synchronous, meaning the fixed leader waits for ack from all the followers (that are to be replicated synchronously) before committing an entry, the entire cluster would become unavailable if even a single node goes down.
Overall, all the distributed systems mentioned above relied on a single entity to make critical decisions. In some essence, decisions by a single entity avoid the split brain problem, (split brain: when network partitions cause multiple nodes to assume leadership or control, leading to conflicting actions and data inconsistency). However, this single point of failure makes distributed systems unreliable as nodes can go down at any time, making the systems unavailable temporarily, or even permanently if a human is not involved.
How Raft addresses these problems?
The above limitations highlight the need for decentralization and replication in modern distributed systems to ensure High Availability, at the same time handling split-brain issues.
A solution for coping with the split-brain problem is majority-vote. Raft is one such consensus algorithm based on a majority-vote. It ensures that the state is first replicated across the majority of servers to mark the entry as safe which would ensure it will be eventually replicated in the entire cluster. This in turn also avoids electing multiple leaders in case of a network partition as the candidate would require votes from the majority of servers in the system, and only the leader with the most up-to-date log would be elected.
Hence, the failure of some nodes shouldn't affect the availability of the system, and network partitions shouldn't cause any data inconsistencies. Of course, the trade-off being that the ack would be sent to the client only when the entry is replicated to atleast a majority of raft servers.
Raft may not be the ultimate solution for everything, it'd always depend on what we are trying to achieve with our storage systems and what guarantees we require for our use-case.
Raft Algorithm
Raft was designed for easier understandability (relative to consensus algorithms like Paxos). It is claimed to be as equivalent to (multi) Paxos and as efficient. The algorithm is decomposed into three independent sub-problems: Leader Election, Log Replication and Safety
Leader Election
A node in a distributed system can go down at any time, and if it's a leader node it should be replaced by another node through the leader election process.
The server can be in any of these three states at a given point in time: Leader, Follower, or Candidate. They all start as followers.
Q. How do followers stay aware of the leader?
A. The leader sends periodic heartbeats (RPCs). If the follower(s) receives no communication, it assumes there's no leader and starts an election.
The follower(s) then convert its state to candidate, and issues request vote RPCs to all the servers to collect votes for itself to be elected as a leader.
Each election begins with something called a term. If a leader goes down, a new term would begin for the new leader. The raft log stores commands with term and index information.
Log Replication
Once we have a leader, it starts servicing client requests. The leader appends the command to its log and issues append entries to all the followers to replicate the entry.
Once the entry is replicated to majority of the servers, it is marked as committed. And this is when the leader executes the entry on its state machine and signals followers to do the same, ensuring all nodes are consistent.
Q. How raft ensures the leader and followers logs are consistent?
A. It does so by defining the log matching property
-
Property 1: If two entries in different logs have the same index and term, then they store the same command.
- Guaranteed from the fact that the leader creates at most one entry with an index in its term.
-
Property 2: If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
- When the leader sends an AppendEntry RPCs, it includes the term number and index of the entry in its log that precedes the new one. If the follower does not have this entry it refuses the new entry. The leader will overwrite followers' logs who have such inconsistencies. Read more in the paper on the technical details of how this overwriting is done.
Safety
Q. Who can be a leader?
A. Election Restriction:
- The candidate's log should be as up-to-date as any other log in the majority
- The log with later term is more up to date
- If terms are same, the longer log is more up to date
- A candidate must get votes from a majority of the cluster, the voter denies its vote if its own log is more up-to-date than the candidate's log.
This means every committed entry would be present on at least one of the servers.
Q. How would the new leader handle committing entries from previous terms?
A. We will discuss the figure 8 of raft paper that addresses one of the raft's safety properties about "committing entries from previous terms". I feel it's important to discuss this as there are a good amount of questions and discussions around it on various discussion forums.
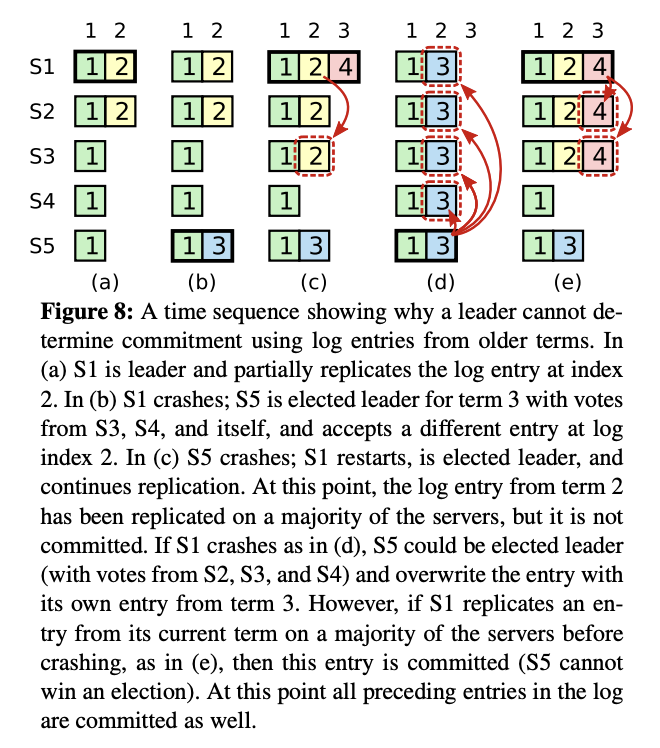
Image Source: Raft Paper: Figure 8
The figure essentially shows two possible scenarios:
- a -> b -> c -> d
- a -> b -> c -> e
For the common parts,
-
in (a) s1 is the leader with term 2, and replicates an entry for server s2 at index 2.
-
in (b) s1 crashed, so a new leader has to be elected. s5 sets its term as 3 and gets votes from s3, s4, and itself, as its term number 3 is higher than s3 and s4 current term. And hence, becomes a leader as it receives votes from a majority.
-
in (c) s5 crashes, but could not replicate any entry from its term to any of the servers. Also, s1 restarts and becomes a leader, let's say by getting votes from itself, s2 and s3, with its current term as 4. It replicates an entry to s2 and s3 i.e. majority of the servers from term 2 (not the current term). Note that these entries are not committed.
now, two scenarios emerge:
-
scenario 1: c -> d in (d) s5 is elected leader from votes from s2, s3 and s4, as its log term is greater than the ones mentioned. It overwrites an entry from term 3 (not its current term) on all the servers.
-
but in an alternate scenario 2: c -> e if in (c) s1 replicates an entry from its current term (term 4) on a majority of servers, then this entry is committed, and s5 now won't be able to win the election (since the log from current term 4 is replicated on the majority of servers and s5's log had a lower term, so wouldn't quality to be a leader.
So we saw in scenario c -> d that a log entry can still be overwritten even if it is replicated on the majority of servers, note that the entry replicated was not from the leader's current term. So as a result raft would not commit the log entry from a previous term even if it is replicated on a majority of servers, as it could be overwritten. It would commit the entry only if it is from its current term and replicated on a majority of servers, in which case no server that doesn't have the entry from this term (like s5) can become a leader, their request for a vote would be rejected by at least one of the server.
Also, when the entry from the current term is committed, indirectly, entries from all previous terms would be marked as committed as well because of the log-matching property we stated previously.
Q. Raft paper says leader will not commit entries from previous terms until it commits a new entry from its current term, in that case will it block any commands getting executed on state machine until a new entry arrives?
A. No, the newly-formed leader would replicate and commit a no-op command, which would ensure and implicitly consider all the previous commands as committed
Discussion
We did touch upon the crux of the algorithm, but these notes are still at a higher level, but it should make it easier to read the paper while referring to these notes. The paper is very detailed and the algorithm is very well explained.
The paper, also talks about how things are simplified in raft, for example, raft simplifies the leader election algorithm using a randomized approach; it uses randomized election timeouts to avoid a situation when many followers become candidates at same time and request votes. The randomization ensures that split votes are rare and are resolved quickly.
Overall, when compared to other consensus algorithms like, Paxos, which has been around longer, Raft is noted to be much easier to implement and understand. Paxos is well-respected but notoriously complex, often requiring variations to be practically usable. In my opinion, raft seems only simpler when compared with other consensus algorithms; it is still complex and challenging to implement in general.
What's next?
Next, I suggest you go ahead and read the Raft paper, given you have a higher-level idea of some of the moving parts. You might have questions based on the text you read here. Now should be a good time to get answers to your questions by reading through the paper, referencing other blog posts from experts, or asking below directly in my twitter post's comment section. Read and try to make sense of the figures listed in the paper for various cases. If you feel stuck - ask! If I can, I’ll answer; otherwise, I’ll try to find the answer for both of us.
From my side, my next post should be on implementing leader election in go. I'll take some time to come back to it. Meanwhile, please let me know if that sounds like a good next step or if you want me to keep it more use-case driven and top-down. For example, I could start implementing a single node key-value server, then start implementing raft and write the k-v store on top of it to make it replicated, and maybe add sharding ability. Let me know your thoughts and suggestions.
