This article was originally published at Towards Data Science Medium Publication.
Enabling a Powerful Search Capability — From Design Decisions to everything behind the scenes
At Koverhoop, we are building a couple of large-scale projects in the Insurance domain. For one of our projects, which is a Multi-tenant Group Insurance Brokerage Platform, klient.ca, we were to build a Powerful Search Capability, by being able to denormalize incoming events in real-time. Also, we wanted our search results to appear as we type. Below is what we were able to achieve, and in this post, I’ll be talking about the core infrastructure, how we fully automate its deployment, and how you too can set it up really quick.
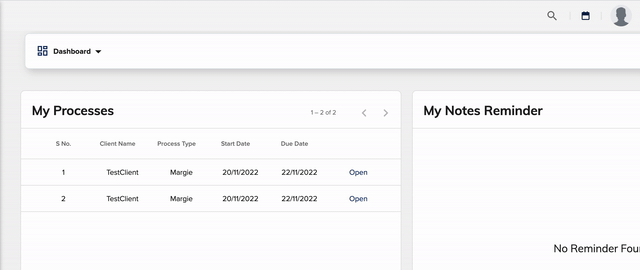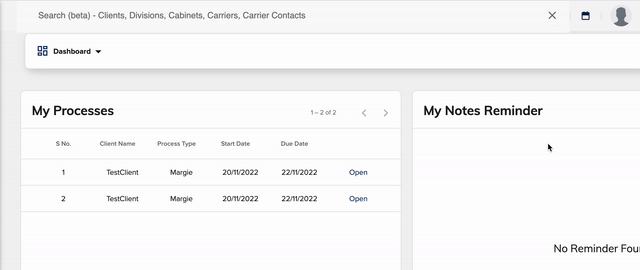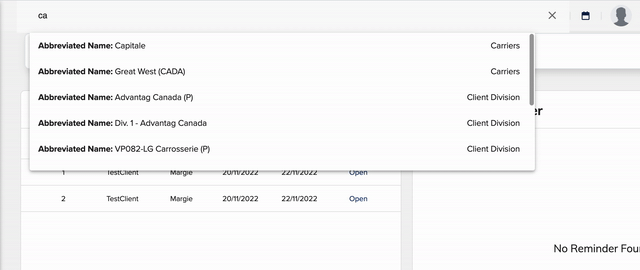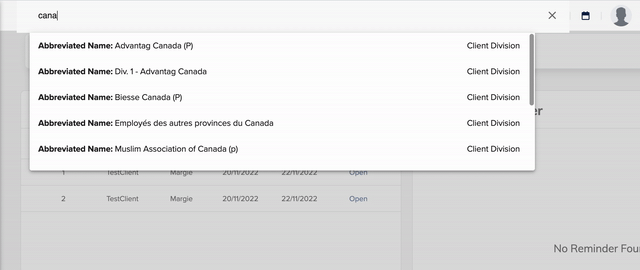
Search in Action
Also, consider this as a two-part series, where I’ll be discussing the following:
Part 1: Understanding the stack used to power this Search Capability and deploying it using Docker and docker-compose. (this post)
Part 2: Making a Scalable Production deployment of these services using Kubernetes. (yet to be published)
Problem Definition and Decisions Taken
To build a search engine that was quick, and real-time we had to make certain design decisions. We use Postgres as our primary database. So we had the following options we could use:
- Query the Postgres database directly for each character we type in the search bar. 😐
- Use an effective search database like Elasticsearch, and store data in a denormalized fashion. 🤔
Considering, we were already a multi-tenant application, also the entities to be searched for could require processing a lot of joins (if we used Postgres), and the scale we were projecting was quite high, we decided to not use the former option of querying the database directly, for performance implications and latency-related concerns.
So we had to decide on a reliable, and efficient way to move data from Postgres to Elasticsearch in real-time. Again the following decisions were to be made:
- Use Logstash to query the Postgres database at regular intervals and send data to Elasticsearch. 😶
- Or use the Elasticsearch client in our application and CRUD the data both in Postgres and Elasticsearch together. 🧐
- Or use an event-based streaming engine that retrieves events from Postgres’ write-ahead logs, stream them to a stream processing server, enrich the streams, and sink it to Elasticsearch. 🤯
Option 1 was struck out pretty quick as it was not real-time, and even if we query at shorter intervals it would put a significant load on the Postgres server, and also could incur additional query latency and server instability as our data grows. Choosing between the other two options could be a different decision at different companies. We could foresee some issues for our use case if we chose option 2:
- Either, we would need to maintain transactions and rollouts between the two kinds of databases: Postgres and Elasticsearch: we would have to rely on two DBs to make persistent updates; what if one of the DB is slow to acknowledge the update, it might slow down our application.
- Or, if we just allow asynchronous updates for Elaticsearch, then in case of inconsistency how can we retry inserting an event or group of events?
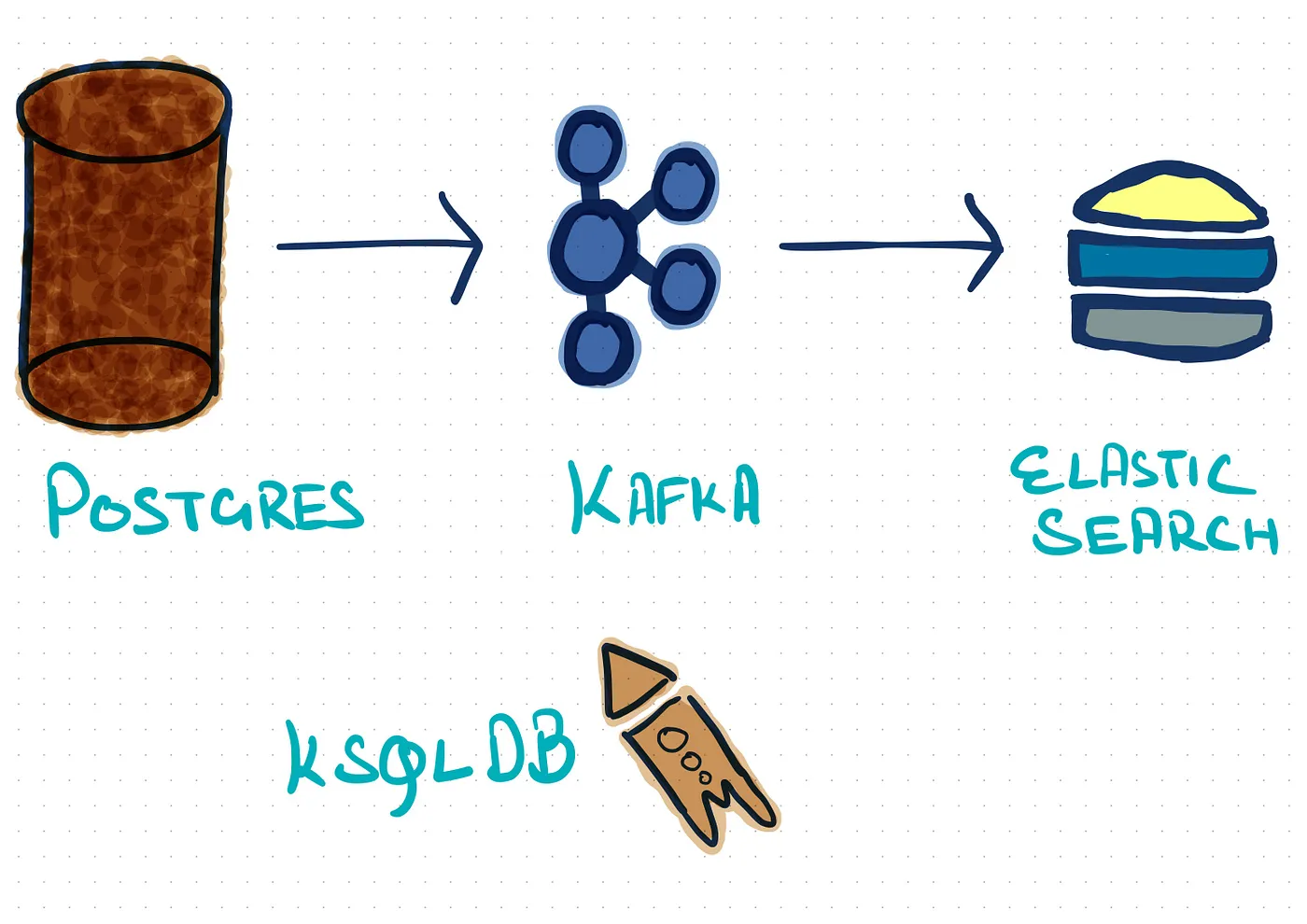
Hence, we decided to go with building an event-based queue infrastructure. Also because we have planned some future use cases and services that were appropriate to be based on events, like notification services, data warehousing, microservice architecture, etc. Without further ado, let’s jump directly into the general overview of the solution and services used.
Basic Overview of the Services
For the implementation of an event-based streaming infrastructure, we decided to go with the Confluent Kafka Stack.
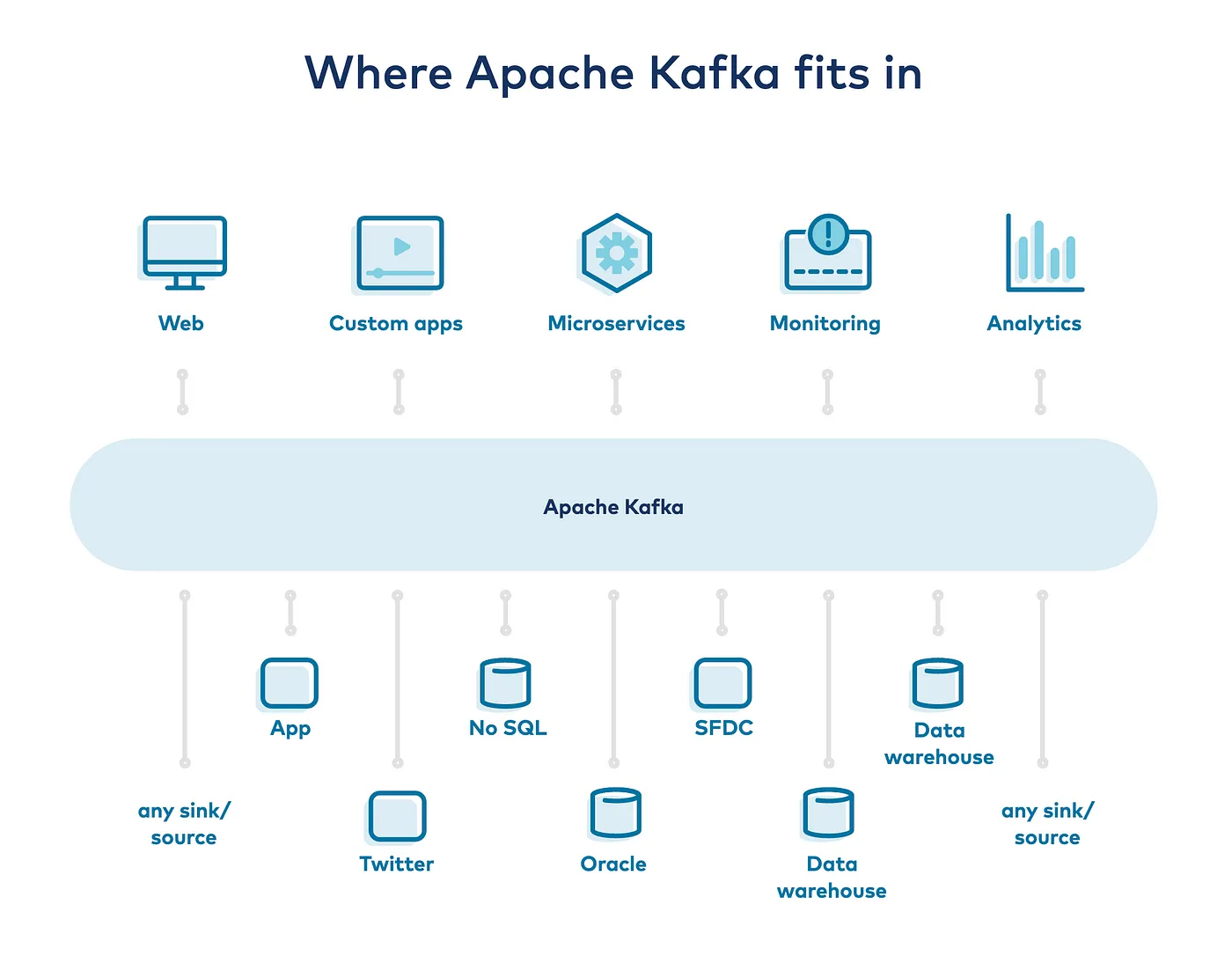
Image Source: Confluent Inc.
Following are the services we incorporated:
Apache Kafka: Kafka is an open-source-based distributed event streaming platform. It would be the main storage area of our database events (inserts, updates, and deletes).
Kafka Connect: We use Kafka-connect to ingest data into Kafka from the Debezium’s Postgres connector, which fetches the events from Postgres WAL files.
At the sink side, we use ElasticSearch Connector to process and load data into Elasticsearch. Connect can run either as a standalone application, or as a fault-tolerant, and scalable service for a production environment.
ksqlDB: ksqlDB allows to build a stream processing application over data in Kafka. It uses Kafka-streams internally, to transform events as they come. We used it for enriching events of a particular stream with pre-existing events of other tables already persisted in Kafka that might be relevant for search abilities, for example, the tenant_id from the root table.
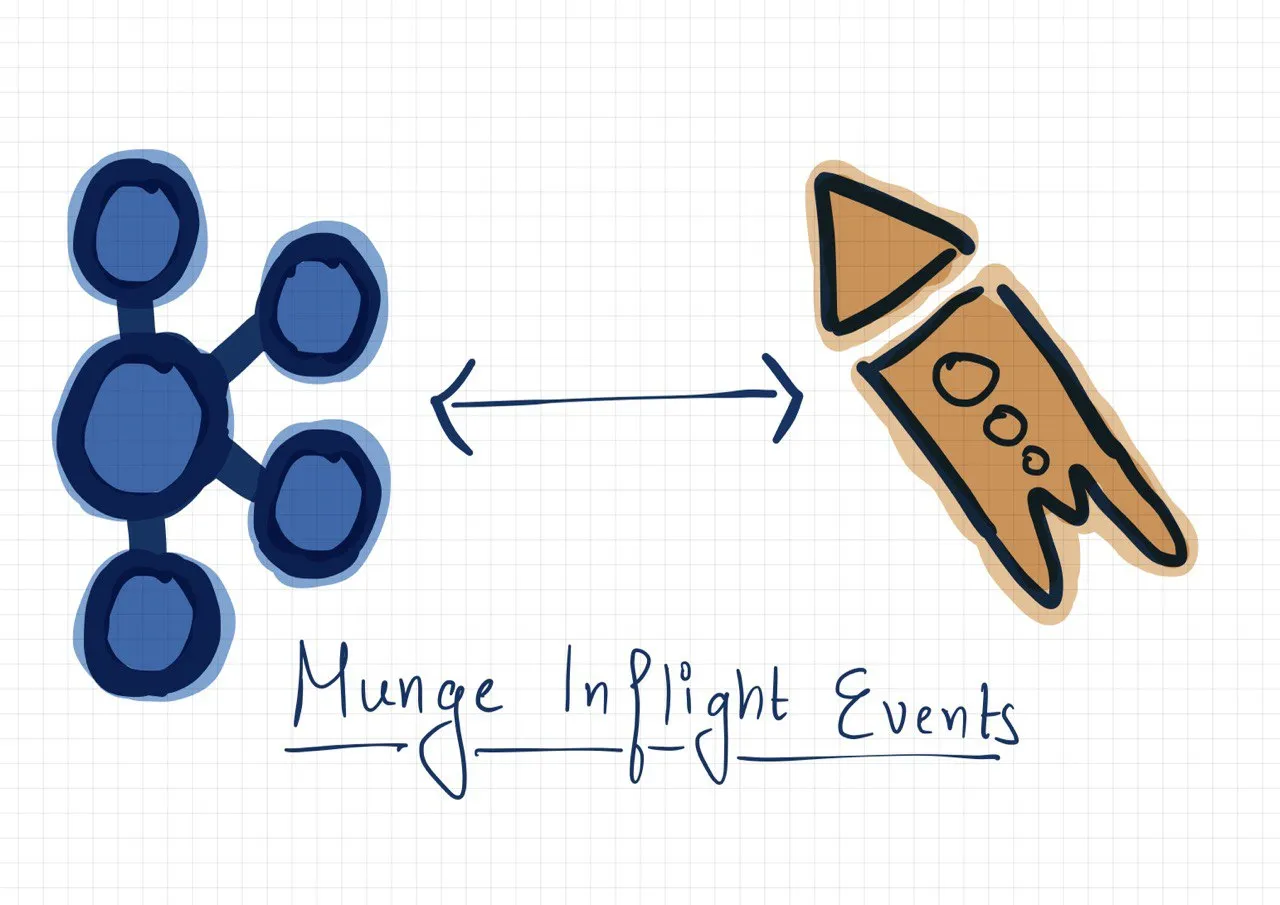
With ksqlDB, it is as easy as writing SQL queries to Filter, Aggregate, Join, and Enrich data. For example, let's assume we are receiving a stream of events on two topics with information related to brands and brand_products. Considering this as a multi-tenant data source, we need to enrich brand_products with tenant_id which is currently only associated with brands. Then we can use these enriched records and store them in Elasticsearch in a denormalized form (to make the search work).
We can set up a KStream using a topic:
CREATE STREAM “brands”
WITH (
kafka_topic = ‘store.public.brands’,
value_format = ‘avro’
);To use only a few columns and partition the stream by id, we can create a new stream called enriched_brands:
CREATE STREAM “enriched_brands”
WITH (
kafka_topic = ‘enriched_brands’
)
AS
SELECT
CAST(brand.id AS VARCHAR) as “id”,
brand.tenant_id as “tenant_id”,
brand.name as “name”
FROM
“brands” brand
PARTITION BY
CAST(brand.id AS VARCHAR)
EMIT CHANGES;”The set of events can then be materialized by the latest offset in a KTable. We use this so that we can join the current state of brand events with some other stream.
CREATE TABLE “brands_table”
AS
SELECT
id as “id”,
latest_by_offset(tenant_id) as “tenant_id”
FROM
“brands” group by id
EMIT CHANGES;Now we add a new stream called brand_products that has a field brand_id with it, but not tenant_id.
CREATE STREAM “brand_products”
WITH (
kafka_topic = ‘store.public.brand_products’,
value_format = ’avro’
);We can enrich the brand_products with tenant_id using the following join query:
CREATE STREAM “enriched_brand_products”
WITH (
kafka_topic = ‘enriched_brand_products’
) AS
SELECT
“brand”.“id” as”brand_id”,
”brand”.”tenant_id” as ”tenant_id”,
CAST(brand_product.id AS VARCHAR) as ”id”,
brand_product.name AS ”name”
FROM
”brand_products” AS brand_product
INNER JOIN ”brands_table” ”brand”
ON
brand_product.brand_id = ”brand”.”id”
PARTITION BY
CAST(brand_product.id AS VARCHAR)
EMIT CHANGES;Schema Registry: It’s a layer over Kafka for storing metadata of the events you ingest in Kafka. It is based on AVRO schemas and provides a REST interface for storing and retrieving them. It helps in ensuring some schema compatibility checks and their evolution over time.
Configuring the Stack
We use Docker and docker-compose to configure and deploy our services. Below are ready-to-build services written in a docker-compose file that will run Postgres, Elasticsearch, and Kafka-related services. I’ll also explain each of the services mentioned below.
Postgres and Elasticsearch
postgres:
build: services/postgres
container_name: oeso_postgres
volumes:
- database:/var/lib/postgresql/data
env_file:
- .env
ports:
- 5432:5432
networks:
- project_networkDocker-compose service for Postgres
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0
container_name: elasticsearch
volumes:
- ./services/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro
- elasticsearch-database:/usr/share/elasticsearch/data
env_file:
- .env
ports:
- "9200:9200"
- "9300:9300"
networks:
- project_networkDocker-compose service for Elasticsearch
For streaming out the events from the source database, we need to enable logical decoding to allow replication from its logs. As in the case of Postgres, these logs are called Write-Ahead Logs (WAL), and they get written to a file. We need a logical decoding plugin, in our case wal2json to extract easy-to-read information about persistent database changes so that it can be emitted out as events to Kafka.
For setting up the required extensions you may refer to this Postgres Dockerfile.
For both, Elasticsearch and Postgres, we specify some necessary variables in the environment file, to set them up with a username, password, etc.
Zookeeper
zookeeper:
image: confluentinc/cp-zookeeper:6.0.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
networks:
- project_network
Zookeeper, in general, acts as a centralized service to distributed platforms like Kafka, which stores all the metadata like the status of Kafka nodes and keeps track of topics or partitions.
There are plans to run Kafka without a zookeeper, but for now, it is a necessary requirement for managing the cluster.
Kafka Broker
broker:
image: confluentinc/cp-enterprise-kafka:6.0.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
networks:
- project_networkFor the sake of simplicity, we’d be setting up a single-node Kafka cluster. I would be discussing more on multiple brokers cluster in Part 2 of this series.
It is particularly important to understand some configurations we made here for the Kafka broker.
Listeners
As Kafka is designed to be a distributed platform, we need to provide certain ways of allowing Kafka brokers to communicate with each other internally, and with other clients externally based on your network structure. So we do that using listeners, and a listener is a combination of Host, Port, and Protocol.
→ KAFKA_LISTENERS This is a list of host, port, and protocol combination interfaces, the Kafka binds to. By default, it is set to 0.0.0.0; that is listening on all interfaces.
→ KAFKA_ADVERTISED_LISTENERS The values for this is again a combination of host and port which the client will use to connect to a Kafka broker. So if the client is within docker, it can connect to the broker using broker:9092 or if there’s a client external to docker, it is returned localhost:9092 to make the connection. We also need to mention the listener name which is then mapped to an appropriate protocol, to make the connection.
→ KAFKA_LISTENER_SECURITY_PROTOCOL_MAP Here we map a user-defined listener name to the protocol we want to use for communication; It can be either PLAINTEXT (unencrypted) or SSL (encrypted). These names are further used in KAFKA_LISTENERS and KAFKA_ADVERTISED_LISTENERS to use appropriate protocols with host/IP.
As we are configuring only a single-node Kafka cluster, the returned, or let’s say the advertised address to any client is of the same broker itself.
Schema-Registry
schema-registry:
image: confluentinc/cp-schema-registry:6.0.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- zookeeper
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: "zookeeper:2181"
networks:
- project_networkFor a single-node schema-registry, we specify the connection string for the zookeeper, used by the Kafka cluster; to store schema-related data.
Kafka-Connect
connect:
image: confluentinc/cp-kafka-connect:6.0.0
hostname: connect
container_name: connect
volumes:
- "./producers/debezium-debezium-connector-postgresql/:/usr/share/confluent-hub-components/debezium-debezium-connector-postgresql/"
- "./consumers/confluentinc-kafka-connect-elasticsearch/:/usr/share/confluent-hub-components/confluentinc-kafka-connect-elasticsearch/"
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: "broker:9092"
KAFKA_HEAP_OPTS: "-Xms256M -Xmx512M"
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_ZOOKEEPER_CONNECT: "zookeeper:2181"
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-5.5.1.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components"
CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR
networks:
- project_networkWe see some new parameters like:
→ CONNECT_BOOTSTRAP_SERVERS: A set of host and port combinations that are used for establishing the initial connection to the Kafka cluster.
→ CONNECT_KEY_CONVERTER: Used for serializing the key from connect format to a format that is compatible with Kafka. Similarly, for CONNECT_VALUE_CONVERTER we use the AvroConverter for serialization.
It’s pretty important to map volumes for our source and sink connector plugins and specify them in the CONNECT_PLUGIN_PATH
ksqlDB
ksqldb-server:
image: confluentinc/cp-ksqldb-server:6.0.0
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
- schema-registry
ports:
- "8088:8088"
volumes:
- "./producers/debezium-debezium-connector-postgresql/:/usr/share/kafka/plugins/debezium-debezium-connector-postgresql/"
- "./consumers/confluentinc-kafka-connect-elasticsearch/:/usr/share/kafka/plugins/confluentinc-kafka-connect-elasticsearch/"
environment:
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_BOOTSTRAP_SERVERS: "broker:9092"
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true"
KSQL_KSQL_STREAMS_MAX_TASK_IDLE_MS: 2000
KSQL_CONNECT_GROUP_ID: "ksql-connect-cluster"
KSQL_CONNECT_BOOTSTRAP_SERVERS: "broker:9092"
KSQL_CONNECT_KEY_CONVERTER: "io.confluent.connect.avro.AvroConverter"
KSQL_CONNECT_VALUE_CONVERTER: "io.confluent.connect.avro.AvroConverter"
KSQL_CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
KSQL_CONNECT_CONFIG_STORAGE_TOPIC: "ksql-connect-configs"
KSQL_CONNECT_OFFSET_STORAGE_TOPIC: "ksql-connect-offsets"
KSQL_CONNECT_STATUS_STORAGE_TOPIC: "ksql-connect-statuses"
KSQL_CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
KSQL_CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
KSQL_CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
KSQL_CONNECT_PLUGIN_PATH: "/usr/share/kafka/plugins"
networks:
- project_networkIf you don’t intend to use Kafka-Connect and when there is no need to scale Kafka-Connect independent of ksql, you can set the embedded-connect configurations for ksql; which also exposes connect endpoints from the ksqldb-server
Other than that, there’s an environment variable that needs some consideration:
→ KSQL_KSQL_STREAMS_MAX_TASK_IDLE_MS: For current versions of ksqlDB, for stream-table joins, the joining of results can become non-deterministic i.e you may not get a successful join if in real-time the event in the table to be joined isn’t created/updated before the stream event. Configuring this environment variable helps in somewhat waiting for the event to load in the table when an event in the stream arrives for that particular timestamp. This improves join predictability but may cause some performance degradation. Efforts are being put to improve this here.
Actually, if you don’t understand the above clearly, I would suggest you use this config for now, as it just works; it actually needs another post to discuss time synchronization in detail or if you’re still curious, you can watch this video by Matthias J. Sax, from Confluent.
ksqldb-cli:
image: confluentinc/cp-ksqldb-cli:6.0.0
container_name: ksqldb-cli
depends_on:
- broker
- ksqldb-server
entrypoint: /bin/sh
tty: true
networks:
- project_networkIt is pretty handy to use a ksqldb-cli service to try and test streams when you’re in testing or development environments. Even in production environments if you want to explore event-streams or Ktables; or manually create or filter streams. Though it is suggested that you automate stream, table, or topic creation either using ksql or kafka clients or their REST endpoints, which we will discuss below.
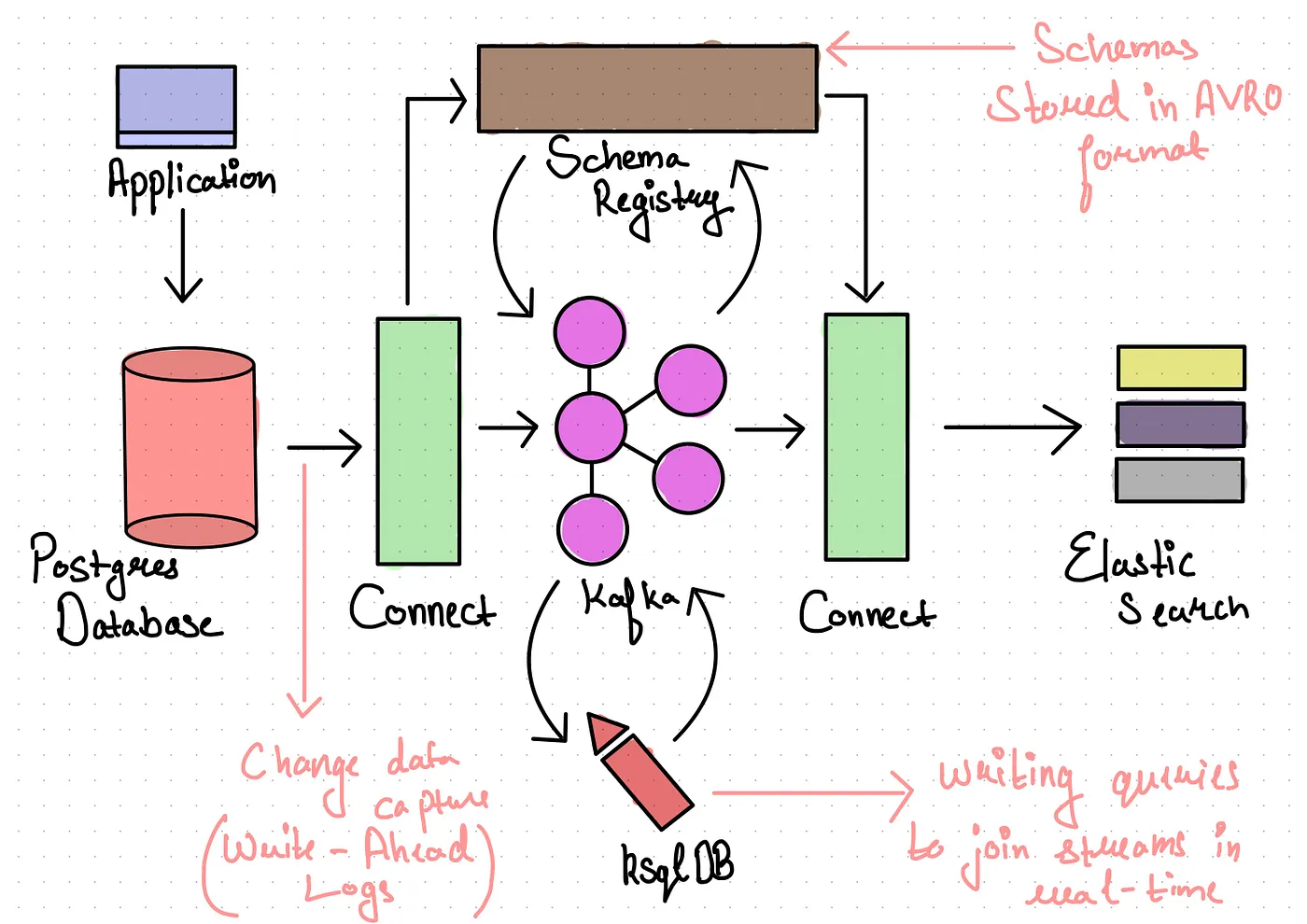
A more detailed look at our architecture, so far.
Initializing data streams
streams-init:
build: jobs/streams-init
container_name: streams-init
depends_on:
- zookeeper
- broker
- schema-registry
- ksqldb-server
- ksqldb-cli
- postgres
- elasticsearch
- connect
env_file:
- .env
environment:
ZOOKEEPER_HOSTS: "zookeeper:2181"
KAFKA_TOPICS: "brands, brand_products"
networks:
- project_networkThe purpose of this service is to initialize the streams and configure things inside Kafka and other services we are using. At the time of deployment, we would not want to manually create topics, streams, connections, etc. on the server. So we utilize the REST services offered for each of the services and write a shell script to automate this process.
Our setup script looks something like the below:
#!/bin/bash
# Setup ENV variables in connectors json files
sed -i "s/POSTGRES_USER/${POSTGRES_USER}/g" connectors/postgres.json
sed -i "s/POSTGRES_PASSWORD/${POSTGRES_PASSWORD}/g" connectors/postgres.json
sed -i "s/POSTGRES_DB/${POSTGRES_DB}/g" connectors/postgres.json
sed -i "s/ELASTIC_PASSWORD/${ELASTIC_PASSWORD}/g" connectors/elasticsearch.json
# Simply wait until original kafka container and zookeeper are started.
export WAIT_HOSTS=zookeeper:2181,broker:9092,schema-registry:8081,ksqldb-server:8088,elasticsearch:9200,connect:8083
export WAIT_HOSTS_TIMEOUT=300
/wait
# Parse string of kafka topics into an array
# https://stackoverflow.com/a/10586169/4587961
kafkatopicsArrayString="$KAFKA_TOPICS"
IFS=', ' read -r -a kafkaTopicsArray <<< "$kafkatopicsArrayString"
# A separate variable for zookeeper hosts.
zookeeperHostsValue=$ZOOKEEPER_HOSTS
# Terminate all queries
curl -s -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "SHOW QUERIES;"}' | \
jq '.[].queries[].id' | \
xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "TERMINATE 'foo';"}'
# Drop All Tables
curl -s -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "SHOW TABLES;"}' | \
jq '.[].tables[].name' | \
xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "DROP TABLE \"foo\";"}'
# Drop All Streams
curl -s -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "SHOW STREAMS;"}' | \
jq '.[].streams[].name' | \
xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d '{"ksql": "DROP STREAM \"foo\";"}'
# Create kafka topic for each topic item from split array of topics.
for newTopic in "${kafkaTopicsArray[@]}"; do
# https://kafka.apache.org/quickstart
curl -X DELETE http://elasticsearch:9200/enriched_$newTopic --user elastic:${ELASTIC_PASSWORD}
curl -X DELETE http://schema-registry:8081/subjects/store.public.$newTopic-value
kafka-topics --create --topic "store.public.$newTopic" --partitions 1 --replication-factor 1 --if-not-exists --zookeeper "$zookeeperHostsValue"
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" --data @schemas/$newTopic.json http://schema-registry:8081/subjects/store.public.$newTopic-value/versions
done
curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d $'{ "ksql": "CREATE STREAM \\"brands\\" WITH (kafka_topic = \'store.public.brands\', value_format = \'avro\');", "streamsProperties": {} }'
curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d $'{ "ksql": "CREATE STREAM \\"enriched_brands\\" WITH ( kafka_topic = \'enriched_brands\' ) AS SELECT CAST(brand.id AS VARCHAR) as \\"id\\", brand.tenant_id as \\"tenant_id\\", brand.name as \\"name\\" from \\"brands\\" brand partition by CAST(brand.id AS VARCHAR) EMIT CHANGES;", "streamsProperties": {} }'
curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d $'{ "ksql": "CREATE STREAM \\"brand_products\\" WITH ( kafka_topic = \'store.public.brand_products\', value_format = \'avro\' );", "streamsProperties": {} }'
curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d $'{ "ksql": "CREATE TABLE \\"brands_table\\" AS SELECT id as \\"id\\", latest_by_offset(tenant_id) as \\"tenant_id\\" FROM \\"brands\\" group by id EMIT CHANGES;", "streamsProperties": {} }'
curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d $'{ "ksql": "CREATE STREAM \\"enriched_brand_products\\" WITH ( kafka_topic = \'enriched_brand_products\' ) AS SELECT \\"brand\\".\\"id\\" as \\"brand_id\\", \\"brand\\".\\"tenant_id\\" as \\"tenant_id\\", CAST(brand_product.id AS VARCHAR) as \\"id\\", brand_product.name AS \\"name\\" FROM \\"brand_products\\" AS brand_product INNER JOIN \\"brands_table\\" \\"brand\\" ON brand_product.brand_id = \\"brand\\".\\"id\\" partition by CAST(brand_product.id AS VARCHAR) EMIT CHANGES;", "streamsProperties": {} }'
curl -X DELETE http://connect:8083/connectors/enriched_writer
curl -X "POST" -H "Content-Type: application/json" --data @connectors/elasticsearch.json http://connect:8083/connectors
curl -X DELETE http://connect:8083/connectors/event_reader
curl -X "POST" -H "Content-Type: application/json" --data @connectors/postgres.json http://connect:8083/connectors
This is what currently works for us:
→ We make sure all the services are ready before we run any jobs over them;
→ We need to be sure the topics exist on Kafka, or we create new ones;
→ Our streams should be functional even if there’s any schema update;
→ Connections are made again, to account for the password or version changes of the underlying data sources or sinks.
The purpose of sharing this setup script is only to demonstrate a way to automate these pipelines. The exact same setup might not work for you, but the idea remains the same for automating your workflows and avoiding any manual work on every deployment across any environment.
To have this Data Infrastructure up and running really quick for you, refer to this Github Repository
So, clone the repository and do a:
cp default.env .env
docker-compose up -d
..on your terminal.
Create brands and brand_products tables inside the store Postgres database:
CREATE TABLE brands (
id serial PRIMARY KEY,
name VARCHAR (50),
tenant_id INTEGER
);CREATE TABLE brand_products (
id serial PRIMARY KEY,
brand_id INTEGER,
name VARCHAR(50)
);Insert some records in the brands table:
INSERT INTO brands VALUES(1, 'Brand Name 1', 1);
INSERT INTO brands VALUES(2, 'Brand Name 2', 1);
INSERT INTO brands VALUES(3, 'Brand Name 3', 2);
INSERT INTO brands VALUES(4, 'Brand Name 4', 2);And some records in brand_products table:
INSERT INTO brand_products VALUES(1, 1, 'Product Name 1');
INSERT INTO brand_products VALUES(2, 2, 'Product Name 2');
INSERT INTO brand_products VALUES(3, 3, 'Product Name 3');
INSERT INTO brand_products VALUES(4, 4, 'Product Name 4');
INSERT INTO brand_products VALUES(5, 1, 'Product Name 5');See the brand_products getting enriched with tenant_id in Elasticsearch:
curl localhost:9200/enriched_brand_products/_search --user elastic:your_passwordI’ll be continuously contributing to the above repository; adding deployment configurations for a multi-node Kafka infrastructure with Kubernetes; writing more connectors; implementing a framework for a plug-and-play architecture, using only the desired services. Feel free to contribute to it or let me know of any Data Engineering problems that you face in your current setup, here.
Next Steps
I hope this post gives you a fair idea on deploying and running a complete Kafka stack, for a basic yet effective use case of building Real-time Stream Processing Applications.
Based on the nature of your product or company, the deployment process may vary to suit your requirements. I do have plans to address the scalability aspect of such a system in the next part of this series which would be about deploying such an infrastructure on Kubernetes, for exactly the same use case.