This article was originally published at Better Programming Medium Publication.
Hands-on implementation based on the MapReduce paper
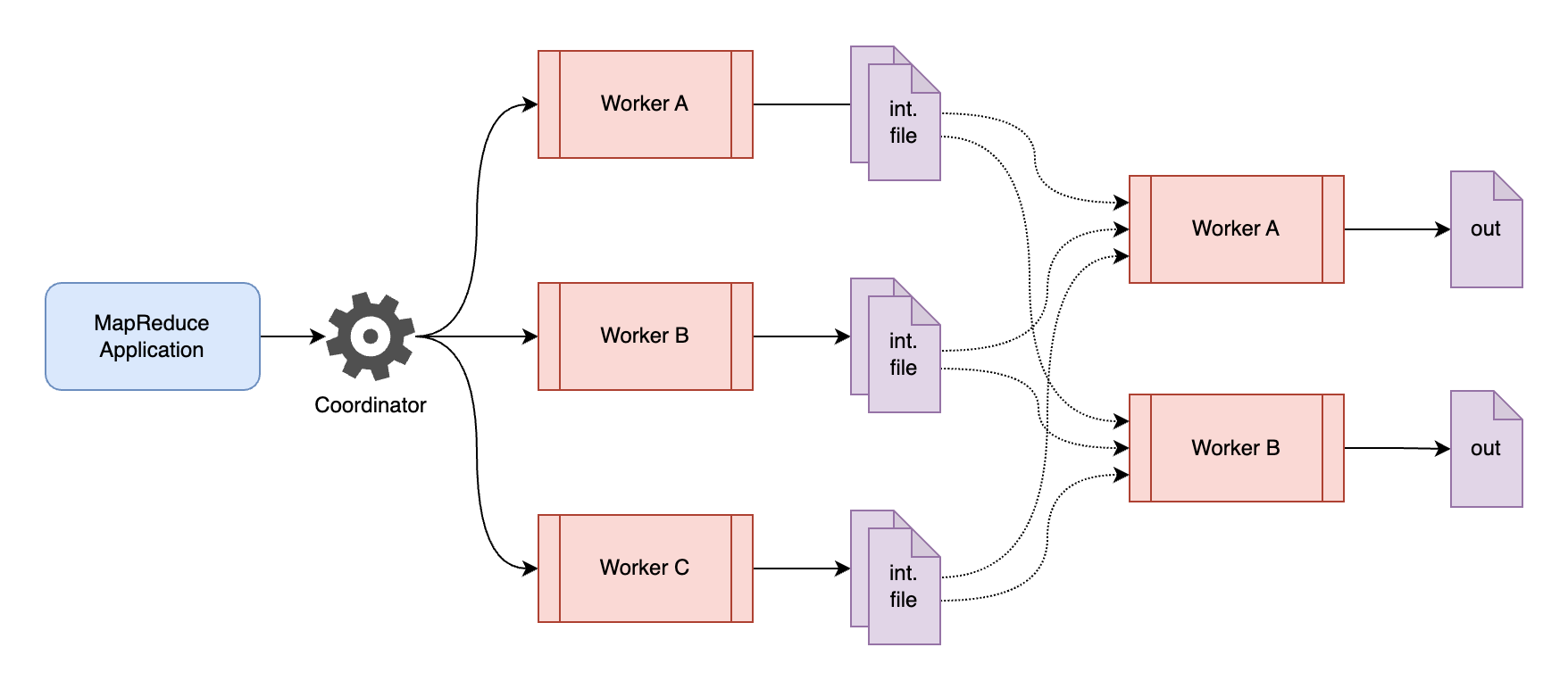
MapReduce is a programming model developed at Google and is used to process large datasets by distributing compute onto commodity hardware. It has been heavily used for big data processing, including but not limited to building search indices, sorting, distributed grep, etc.
In this post, we’d be building a Distributed MapReduce system, as per the MapReduce paper, which would have the ability to allow application developers to use it for building MapReduce applications.
The main purpose here is to learn about distributed systems by actually building one. Implementing a distributed system involves working with various components like networking, communication protocols, data replication, fault tolerance, and concurrency control. By building and deploying a distributed system, we gain firsthand experience with these concepts and get a practical understanding of how they work together.
MapReduce is a relatively simpler system and implementing it is a good first exercise when learning to build distributed systems.
The system we’ll build will abstract complex details like distributed computations from the application developer. Of course, this would lead to restricting the programming model as well, which in a way, would help to parallelize and distribute computations and provide fault tolerance easily.
Some familiarity with Golang, the RPC model, and concurrency constructs like goroutines and wait-broadcast is required. At the end of this post, I do provide a link to a GitHub repo with all the code and instructions to run it.
Introduction
The MapReduce paper was authored by two engineers from Google, Jeff Dean and Sanjaya Ghemawat. They were the ones who also brought GFS, Spanner, BigTable, and much more stuff to Google.
We will refer to some excerpts from the MapReduce paper during implementation.
A simple MapReduce application code for word-count looks like the following:
func map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1")
func reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v)
Emit(AsString(result))Here the map function assigns a value 1 and emits key-value pairs as intermediate data. From this intermediate data, all the values associated with each key are passed to the reduce function to add all the 1s for that particular key and output the result.
The above is the code application developers would plug into the MapReduce System. Our goal for this post is to develop a system that takes in that code and computes the result, handling all the runtime and parallelism, so the application developers won’t have to worry about them.
Implementation
Let’s say we have a large text file, which we would partition into M number of file splits. Each file split would be assigned as a task to a machine in the cluster that runs in parallel and applies the map function on the file split (e.g., the function defined above). These map invocations would be distributed across many machines. We will have all the processes running on the same machine for simplicity, but we’ll still see parallelism as we run them on a multi-core processor.
We would have a special single process, which we’ll call the coordinator (referred to as “master” in the paper). The coordinator is responsible for assigning tasks to the workers, and the workers are actually the ones responsible for executing those map and reduce tasks.
Users provide — the data to be processed, the MapReduce application code, and the number of reduce workers, NReduce. NReduce would also refer to the total number of partitions based on which the intermediate data from the map phase would be stored.
Design
At a high level, a single coordinator and multiple worker processes are spawned. Workers polls for available tasks from the coordinator through RPC calls. The coordinator looks for available tasks, records the startTime for the task, updates its status, and returns it to the worker. The workers perform map or reduce tasks based on the task type and make another RPC call to the coordinator to mark the task as completed once it successfully finishes its execution.
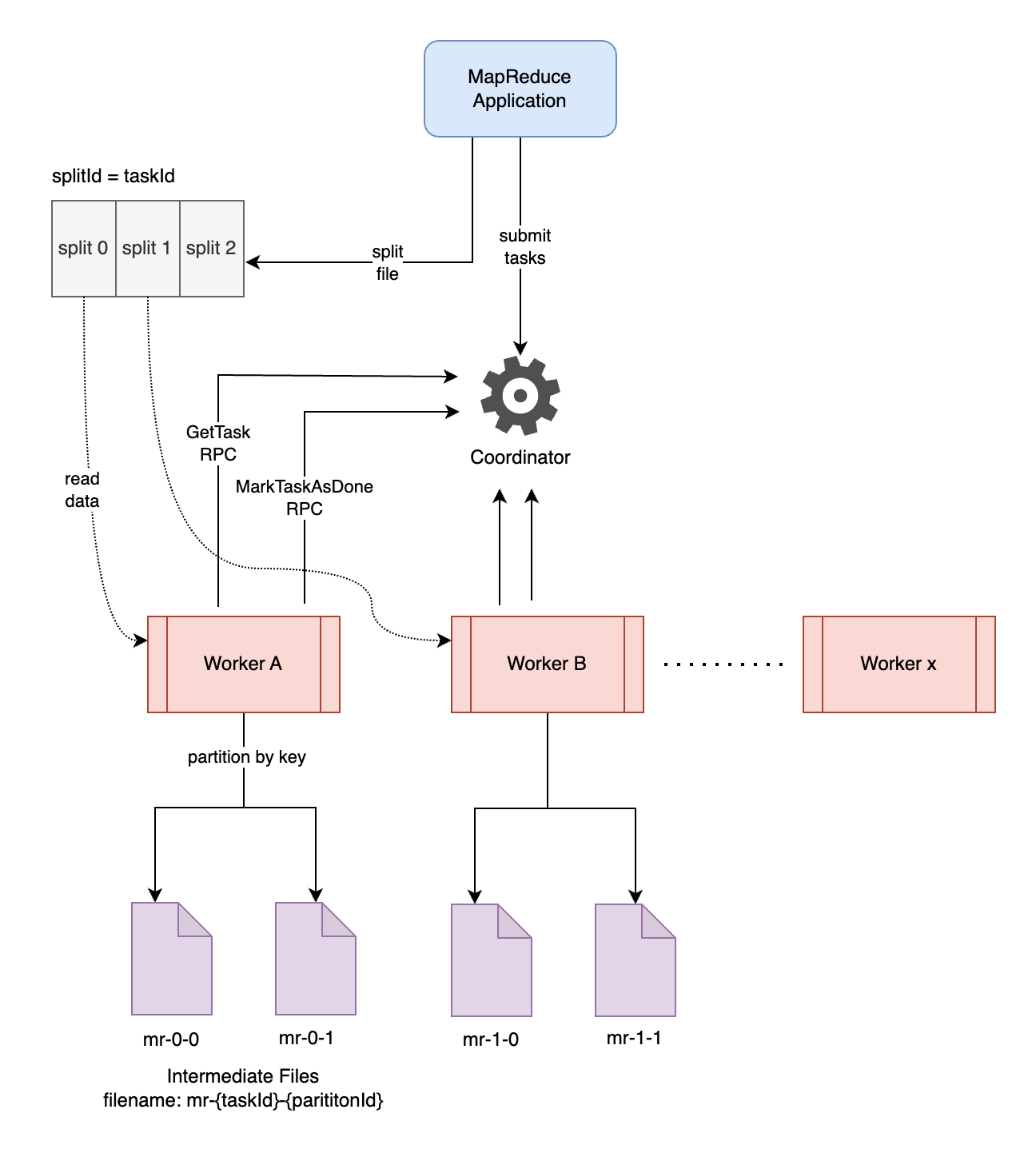
Map Phase
The first phase is the map phase. The reduce phase can only start once the map phase is finished. The input file is split into M files, which translates to M map tasks. For each map task, the map function is applied to the data, and the data is stored in a partitioned way (i.e., in multiple files/buckets) using the hash function on the key.
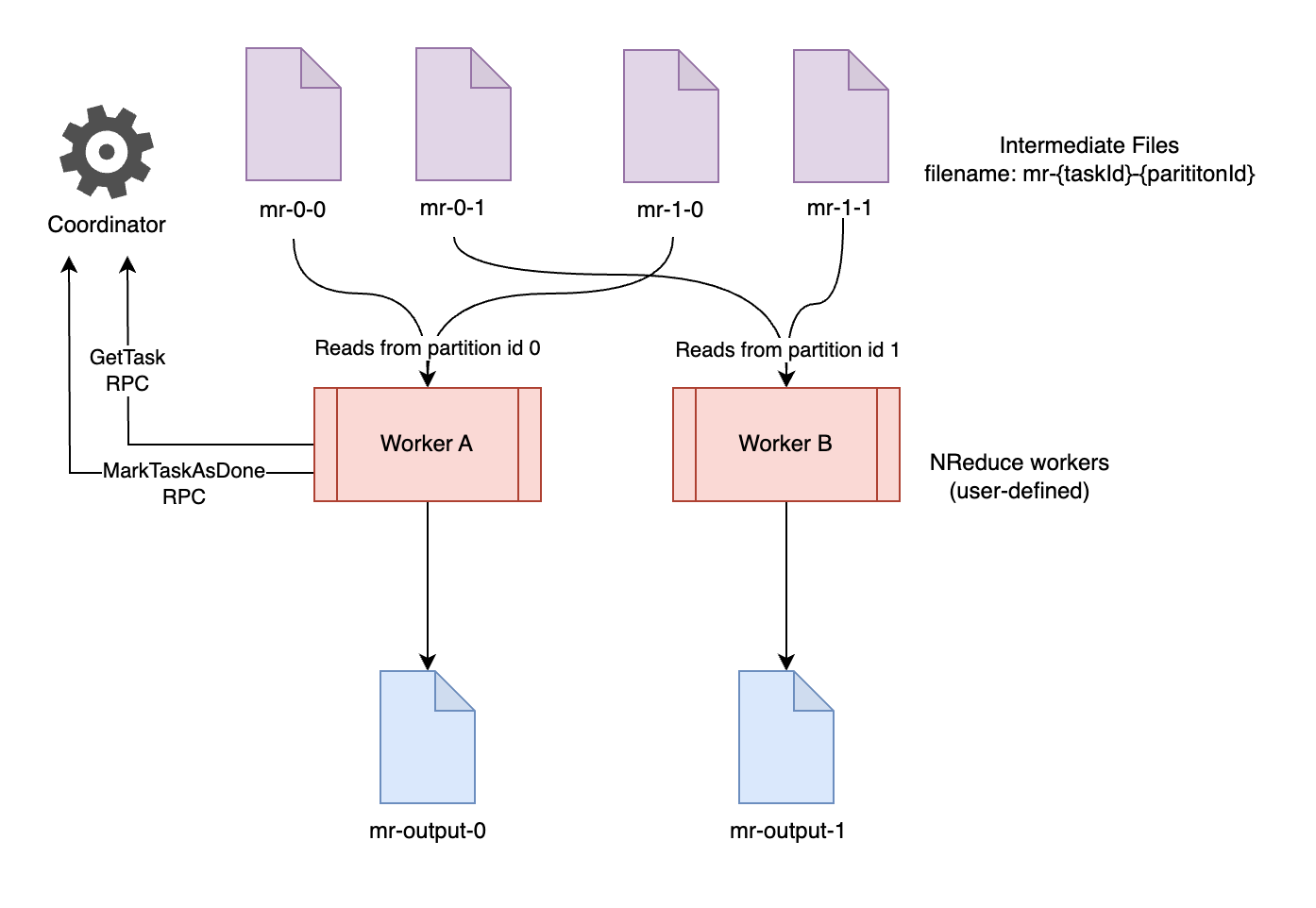
Reduce Phase
Once all map tasks are completed — the coordinator starts assigning the reduce tasks. For each reduce task, the worker reads all the data from each partition into the memory, applies the reduce function to it, and stores the output to a file suffixed with the partition-id.
Code
Let’s start with the entry point file, main.go.
package main
import (
"fmt"
"log"
mr "mapreduce/internal"
"os"
"plugin"
)
func main() {
iscoord := os.Args[1] == "mrcoordinator"
isworker := os.Args[1] == "mrworker"
if iscoord {
runCoordinator()
} else if isworker {
runWorker()
} else {
fmt.Fprintf(os.Stderr, "Invalid arguments\n")
os.Exit(1)
}
}
func runWorker() {
// to implement
}
func runCoordinator() {
// to implement
}
func loadPlugin(filename string) (func(string, string) []mr.KeyValue, func(string, []string) string) {
// to implement
}This file uses command-line arguments to infer which process to launch — the coordinator or the worker. We also have a loadPlugin utility function that allows application developers to load the application code into the MR system.
Find the complete main.go code here.
RPC implementation
We would have two RPC calls coming from the workers, namely:
- GetTask()
- MarkTaskAsDone()
Below we define the arguments and return structs for each of the RPC methods:
package mr
import (
"os"
"strconv"
)
type GetTaskArgs struct {
}
type GetTaskReply struct {
Name string
Number int
NReduce int
Type TaskType
}
type MarkTaskAsDoneArgs struct {
Name string
Type TaskType
}
type MarkTaskAsDoneReply struct {
}
type TaskType string
var (
mType TaskType = "map"
rType TaskType = "reduce"
)
func coordinatorSock() string {
s := "/var/tmp/mr-"
s += strconv.Itoa(os.Getuid())
return s
}GetTask RPC
GetTaskArgs: We leave this struct empty as the GetTask RPC does not require any arguments
GetTaskReply:
Name: refers to the filename through which the data is to be read from
Number: represents the task number from each phase which we use for referring to intermediate and output files
NReduce: refers to partition numbers
Type: type of task — map or reduce
MarkTaskAsDone RPC
MarkTaskAsDoneArgs:
Name: the name of the task that needs to be marked as done
Type: type of the task — map or reduce
MarkTaskAsDoneReply: We leave this struct empty as MarkTaskAsDone does not require to return anything to the process calling this method
Find the complete RPC implementation code here.
Implementing coordinator
package mr
import (
"errors"
"fmt"
"log"
"net"
"net/http"
"net/rpc"
"os"
"sync"
"time"
)
type Coordinator struct {
mTasks map[string]*TaskMeta
rTasks map[string]*TaskMeta
cond *sync.Cond
mRemaining int
rRemaining int
nReduce int
}
type TaskMeta struct {
number int
startTime time.Time
status Status
}
type Status string
var (
unstarted Status = "unstarted"
inprogress Status = "inprogress"
completed Status = "completed"
)
func (c *Coordinator) getMTask() (string, int) {
// to implement
}
func (c *Coordinator) getRTask() (string, int) {
// to implement
}
func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error {
// to implement
}
func (c *Coordinator) UpdateTaskStatus(args *UpdateTaskStatusArgs, reply *UpdateTaskStatusReply) error {
// to implement
}
func (c *Coordinator) rescheduler() {
// to implement
}
func (c *Coordinator) server() {
// to implement
}
func (c *Coordinator) Done() bool {
// to implement
}
func MakeCoordinator(files []string, nReduce int) *Coordinator {
mTasks := map[string]*TaskMeta{}
for i, file := range files {
mTasks[file] = &TaskMeta{
number: i,
status: unstarted,
}
}
rTasks := map[string]*TaskMeta{}
for i := 0; i < nReduce; i++ {
rTasks[fmt.Sprintf("%d", i)] = &TaskMeta{
number: i,
status: unstarted,
}
}
mu := sync.Mutex{}
cond := sync.NewCond(&mu)
c := Coordinator{
mTasks: mTasks,
rTasks: rTasks,
mRemaining: len(files),
rRemaining: nReduce,
nReduce: nReduce,
cond: cond,
}
go c.rescheduler()
c.server()
return &c
}The MakeCoordinator function is responsible for the following:
- Initiating the coordinator struct:
mTasksis a key value map for the tasks of the typemapcontaining thenameof the task as the key and metadata of the task, like the tasknumber,statusas the value. We also have astartTimefield that gets populated when the task is picked. Similarly, we populaterTasksfor the task of typereduce. - Running the rescheduler() goroutine (which we discuss below).
- Running the RPC server.
The coordinator struct includes the following methods:
GetTask(args, reply)
This method is repeatedly called by the worker(s) through an RPC client, polling the coordinator for a task.
As the worker would call this method concurrently, we would need to use a lock when accessing or writing to the shared data structure.
We will check if there are any map tasks remaining by looking up the value of mRemaining, if yes, we would try to fetch a map task.
The task status and mRemaining keep getting updated concurrently by other goroutines, so we might have to keep iterating until we find a task with status unstarted and return it or until the mRemaining becomes 0. As an implementation detail, instead of continuously locking and unlocking (also called busy-waiting), we use Golang’s wait-broadcast primitives to prevent repeated locking overheads.
So we call wait() on the conditional variable if no task is returned. In a different goroutine (the rescheduler(), which we discuss below), the broadcast method is called if any tasks are to be rescheduled or if all the tasks of a particular phase or both phases are completed.
If mRemaining turns to 0, we then move to fetch reduce tasks, so, if rRemaining > 0, we would try to fetch a reduce task similar to how we fetched the map one, described above. If even rRemaining turns to 0 we can assume the task is completed and exit by returning a message stating the same.
getMTask() and getRTask():
This method simply searches for an unstarted task in the mTasks / rTasks map. If found, updates the startTime and changes the status to inprogress, if not found, return an empty string for the task name and -1 for the task number.
MarkTaskAsDone()
The workers call this method when they successfully complete the task assigned to them. Here we again acquire a lock and set the task status as completed and reduce the value of mRemaining or rRemaining by 1.
rescheduler()
While instantiating the coordinator, we also spawn a goroutine rescheduler(). It serves as a background goroutine that looks for tasks that are inprogress for more than 10 seconds and reschedules them by updating their status to unstarted.
Alternatively, we could have spawned a new goroutine whenever we handed over a task to the worker. This goroutine would sleep for 10 seconds and then check whether that task was completed. If not, it would reschedule the task by changing its status to unstarted.
Done()
This method is continuously called in the runCoordinator() method (from the main.go file) to see if the application submitted to the coordinator has been successfully executed or not. To implement this, we just return True if the rRemaining has converged to 0.
server()
This method registers the coordinator instance to instantiate an RPC server and serves requests on a new goroutine.
Find the complete Coordinator implementation code here.
Implementing worker
package mr
import (
"log"
)
type KeyValue struct {
Key string
Value string
}
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
reply, err := CallGetTask()
if err != nil {
log.Fatal(err)
}
if reply.Type == mType {
executeMTask(reply.Name, reply.Number, reply.NReduce, mapf)
CallMarkTaskAsDone(mType, reply.Name)
} else {
executeRTask(reply.Number, reducef)
CallMarkTaskAsDone(rType, reply.Name)
}
}
}
func executeMTask(filename string, mNumber, nReduce int, mapf func(string, string) []KeyValue) {
// to implement
}
func executeRTask(rNumber int, reducef func(string, []string) string) {
// to implement
}
func CallGetTask() (*GetTaskReply, error) {
// to implement
}
func CallMarkTaskAsDone(typ TaskType, name string) error {
// to implement
}Worker()
This function continuously makes RPC calls (GetTask()) to the coordinator RPC server to fetch a task. Based on the fetched task type, it calls the appropriate task method and makes another RPC call to mark the task as done.
executeMTask() — Executes a task of type: Map
This function reads the file, passes the data through the plugged-in map function to generate the intermediate key-value data, and passes the key of a pair through a hash function to generate filenames with partition-id and store the key-value pairs accordingly in appropriate files.
executeRTask() — Executes a task of type: Reduce
This function reads all the key-value pairs from files with the partition-id (or reduce-task number) returned by the RPC server, sorts the data by key, passes each key’s data to the plugged-in reduce function, and saves the output to a file suffixed with the partition-id.
CallGetTask() — Makes a GetTask() RPC call to the coordinator
CallMarkTaskAsDone()— Makes a MarkTaskAsDone() RPC call to the coordinator to allow the coordinator to mark the task as completed.
Find the complete worker implementation code here.
—
That should be all for a simple implementation of a Distributed MapReduce.
You can also clone this repository and follow the readme to run the MapReduce system through a wordcount example.
What’s Left?
There’s still more stuff the paper discusses that we did not address in this post to keep things simpler. One of them is a technique called Backup Tasks. In a distributed system where commodity machines are used, some of the machines can usually take a long time to complete map or reduce tasks, such a machine in this paper is referred to as a straggler.
A solution proposed in the paper to alleviate this problem is — when a MapReduce operation is close to completion, the coordinator schedules backup executions of the remaining inprogress tasks. The task is marked completed when either of the primary or backup tasks execution has been completed.
Conclusion
MapReduce gave a great boost to big cluster computation. It allowed developers with no background in distributed systems to process very large datasets in parallel without letting them worry about distributing compute and debugging clusters.
A lot of other distributed computing systems like Spark, which is also a system inspired by MapReduce, address some shortcomings of MapReduce. For example, one of the things that became a bottleneck in a system like MapReduce is that it stores intermediate data in disks, which increases the overall latency due to reading and writing data to networked disks. Spark, on the other hand, retains data in memory for use between different steps.
In their research paper, the creators of Spark, Matei Zaharia et al., stated that they were motivated to develop Spark because they found MapReduce unsuitable for certain types of applications, such as iterative algorithms and interactive data analysis.
They also noted that MapReduce has limitations regarding its memory usage and its support for real-time data processing.
Having said that, MapReduce serves as a great foundation for understanding and building distributed systems. We would see more advanced systems that make different trade-offs in future articles.